First published on Synthesio’s tech blog
My first contribution to Elasticsearch
At Synthesio, we use Elasticsearch quite a bit. Or a whole lot, actually. As of today, we have a dozen clusters deployed on about 360 machines. The biggest of those clusters, the aptly named Blackhole, has (almost) a hundred nodes and stores more than a quarter of a petabyte of data.

Due to this large volume of data, we must design our mapping very carefully. In case you’re not familiar with ES terminology, the mapping is what defines which of the documents’ fields are indexed and thus searchable. A suitable mapping is necessary to ensure that you can query the data the way you want, and that these queries are fast.
Each time we want to add a new piece of data in our documents, we need to think about how to store that data and what to add in the mapping to make it searchable. More often than not, this process is quite straightforward.
But sometimes, there are a few alternative data formats and mappings that we can choose from, and we evaluate them across different criteria, such as:
- will the new mapping support all the queries we want to do on the new data
- how fast will these queries be
- how much additional storage will be used
- how easy will it be to update and extend the mapping in the future, etc.
This is a story about the time our best mapping candidate turned out to be not as good as expected, and how we were able to fix everything by contributing code to our favorite search engine.
Some background on what we wanted to do…
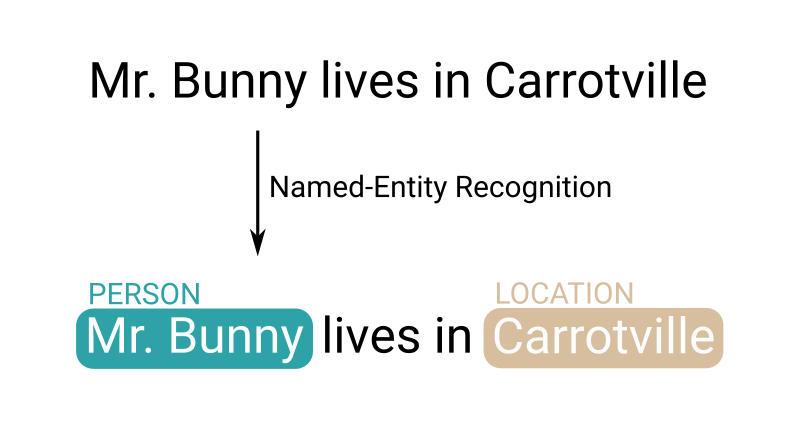
Our documents are social media posts, and as such they most often contain text. We recently worked on detecting the named entities contained in text, and wanted to store them and make them searchable.
Named entities are groups of words that we can assign to one of a few predefined categories such as persons, locations, organizations, events etc.
For example, in the sentence “Mr. Bunny lives in Carrotville”, we would detect “Mr. Bunny” as a person entity, and “Carrotville” as a location entity.
There are many ways to represent this kind of information in Elasticsearch documents. Let’s see what kind of mapping we could use.
You could have one indexed field for each type of named entity:
Document
{
"named_entities": {
"persons": ["Mr. Bunny"],
"locations": ["Carrotville"]
}
}
Mapping
{
"properties": {
"named_entities": {
"properties": {
"persons": {
"type": "keyword"
},
"locations": {
"type": "keyword"
},
"organizations": {
"type": "keyword"
},
"events": {
"type": "keyword"
},
"etc.": "..."
}
}
}
}
Or you could instead use nested documents like so:
Document
{
"named_entities": [
{
"value": "Mr. Bunny",
"category": "person"
},
{
"value": "Carrotville",
"category": "location"
}
]
}
Mapping
{
"properties": {
"named_entities": {
"type": "nested",
"properties": {
"value": {
"type": "keyword"
},
"category": {
"type": "keyword"
}
}
}
}
}
However, with either of those mappings, you cannot make a query to answer a question such as “what are the top entities (of any type) in my documents?”
So we opted for a more ad hoc but simpler mapping, using a simple list of strings, with a prefix to encode the type:
Document
{
"named_entities": [
"PERSON:Mr. Bunny",
"LOCATION:Carrotville"
]
}
Mapping
{
"properties": {
"named_entities": {
"type": "keyword"
}
}
}
Let’s search!
OK, that last mapping is very simple, but is it powerful enough? Let’s see what kind of search queries we can make with it.
To find the top entities in a set of documents, you can use a simple terms aggregation like so:
{
"aggs": {
"top_entities": {
"terms": {
"field": "named_entities"
}
}
}
}
Great! But what if you want to target only a subset of the entity categories? Well, you can use a regular expression as an include parameter in the terms aggregation. For example, if you only want persons and organizations, you can do:
{
"aggs": {
"top_entities": {
"terms": {
"field": "named_entities",
"include": "PERSON:.*|ORGANIZATION:.*"
}
}
}
}
Awesome! And similarly, if you want to exclude a few specific entities, you can use an exclude parameter with a list of terms:
{
"aggs": {
"top_entities": {
"terms": {
"field": "named_entities",
"exclude": [
"PERSON:Mr.Fox",
"ORGANIZATION:Burgercorp"
]
}
}
}
}
That looks great! Thanks to the include and exclude parameters, our very simple mapping is pretty powerful!
The unforeseen problem
OK, so we were already able to do a lot with include and exclude, but let’s try one last thing. What if you want to find all the persons and organizations except a few specific ones? Easy, right? Just add both the include and the exclude like this:
{
"aggs": {
"top_entities": {
"terms": {
"field": "named_entities",
"include": "PERSON:.*|ORGANIZATION:.*",
"exclude": [
"PERSON:Mr.Fox",
"ORGANIZATION:Burgercorp"
]
}
}
}
}
Well, yes, but actually no. Until Elasticsearch 7.11, the query above would return this error:
{
"type": "illegal_argument_exception",
"reason": "Cannot mix a set-based include with a regex-based method"
}
Even though the documentation didn’t say anything about it, if you want to have both an include and an exclude, they have to be both of the same type, either two regular expressions, or two plain lists of terms.
You can’t mix the two.
Dammit.
How to solve a problem while giving back to the community
Unfortunately, we found this error after the mapping was already adopted and deployed. Looks like we missed that last use case when investigating the mapping. And it was a bummer, because filtering categories of entities while removing some specific entities was something we wanted to do.
But apart from this one error, our mapping was working very well for all other use-cases, so we were reluctant to change it. So we asked ourselves, why does this include/exclude type-mixing limitation exist in the first place? Couldn’t we just remove that limitation?
And thus, we set out to explore the vastness of the Elasticsearch code.
It turned out that this part of the code was pretty straightforward, and we quickly became confident that we could indeed lift the limitation, and allow mixing the types. Within a couple days, we had a working proof-of-concept.
With a bit more work, the proof-of-concept became a proper pull request, which got accepted and merged in Elasticsearch v7.11, which was released last week.

All in all, this whole adventure has a happy end: we were able to get our favorite mapping to do all the things we wanted it to do, and as a bonus, we gained a better understanding of some of Elasticsearch internals.
We are very happy to contribute to a piece of software that’s so important for our needs, and we hope that this contribution will be helpful to others.
For more information, feel free to head to Github for the feature request and the subsequent pull request.